
AI vibe coding notes from the basement

As my AI coding journey continues, I’ve been taking notes and reflecting on my experiences. This post is a collection of my thoughts, observations, and loose reflections on the subject. Wherever possible, I try to explain the concepts in a way that’s easy to grasp.
In my AI-Driven Development post, I recommended always striving to build something tangible—something that brings real value to you, your business, or your followers. The majority of the work related to my awesome localstack (which I use commercially for all of my trainings) was actually done by Sonnet 3.5 and Sonnet 3.7 LLMs, all within the Cursor IDE. If you’re curious about the details, feel free to explore the commits and pull requests in both the backend and frontend repositories. At the end of this post, I’ll walk you through a full case study: building a websocket-based live traffic monitor from scratch.
There’s no doubt that LLMs are getting better at planning (ReAct-style reasoning), understanding how complex codebases fit together (using “thinking” models like o1), and of course, writing code (Sonnet 3.5/3.7 has been stellar here). But quite surprisingly, we’re still bottlenecked by the size of the context window. If we exclude the Gemini models—which can handle up to 1 million tokens but arguably sacrifice quality—the effective cap is still around 200k tokens. Grok 3 API hasn’t been released yet, but it may be a game-changer.
There are several charts floating around online showing exponential growth in context window sizes, but this feels like a typical AI influencer move: cherry-pick the best-case scenario to paint a misleading picture.
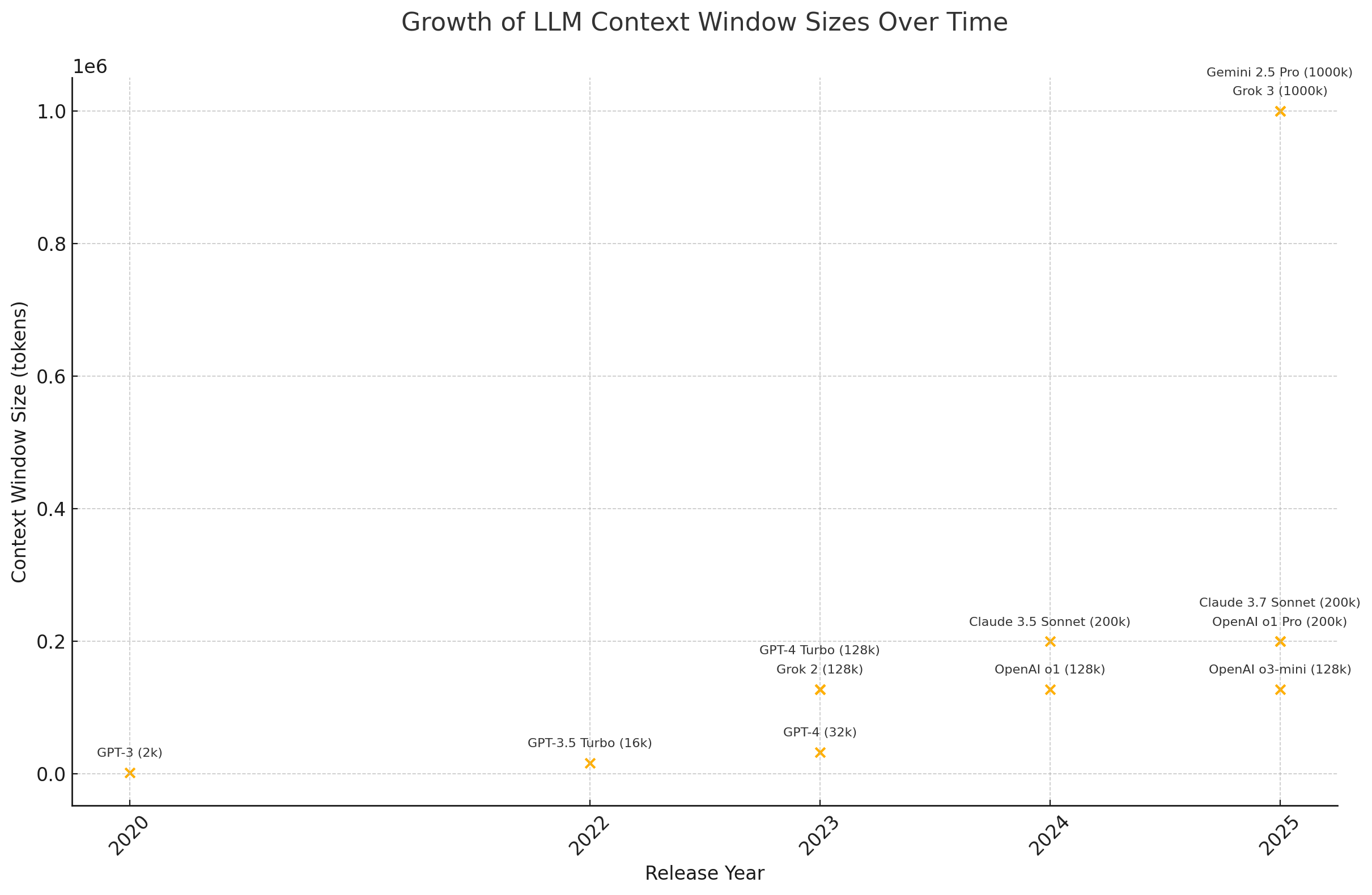
AI coding tools like Cursor add another layer of limitation on top of the raw model capabilities.
Cursor actively optimizes the context window as the Chat session progresses, intelligently pruning non-essential content while preserving critical code and conversation elements.
If you want to send full context requests, you have to pay extra—on top of the base subscription. That means you’re not just paying a flat fee, but also per-request charges. It’s a bit of a bummer, but this is the current reality of AI-assisted coding tools.
And naturally, this brings us to another growing constraint: the cost of LLM calls. More on that later.
Vibe Coding
The viral term “vibe coding” is often used to describe the process of coding with AI assistance. It’s catchy, but also quite ambiguous—it means different things to different people. Those unfamiliar with the latest AI developments might assume that software engineering is now entirely handled by LLMs. This couldn’t be further from the truth.
To make sense of the term, I suggest breaking it down into two distinct categories:
Educated vibe coding
Andrej Karpathy’s now-famous tweet is a great example of educated vibe coding. Karpathy understands how LLMs work better than 99% of the people posting their “AI-generated” code on X. He uses LLMs as a tool to assist his reasoning—not as a replacement for it. More importantly, he uses them to generate code he could easily write himself. That means he understands the code, can debug it, and can take over at any point.
This is also how I try to approach working with AI. Whenever the AI gets stuck, I jump in and take over manually. I guide it not just to generate the code, but also to produce the necessary bash scripts, documentation, tests, etc. In this setup, I’m the leader and the AI is my assistant.
The idea that AI or LLMs can replace a competent human developer is fundamentally flawed. LLMs are powerful tools to help you code faster—but they are not a replacement for critical thinking or engineering skill.
Uneducated vibe coding
On the other hand, uneducated vibe coding is what happens when someone jumps too quickly onto the “no-code” bandwagon. These folks often lack technical background and don’t understand how proper software engineering works. They use AI to generate code without grasping the underlying concepts. There are no tests, no documentation, no bash scripts, no CI/CD. They post their “AI-generated” projects on X and brag about building an app in a few hours—only for their production database secrets to be exposed in every request.
Shrivu Shankar summarizes the issue well:
I regularly look through the source code for those “I built ABC app in N days, with only K experience, using AI tool XYZ” posts and I can confirm that they are rampant with serious security vulnerabilities. I expect this needs to be resolved with a mix of AI using secure-by-default building blocks and coding tool providers establishing security certifications. Humans write insecure code too, but this shouldn’t be a trade-off made for the adoption of AI developer tools.
The issue is further amplified by tools like v0, which are getting increasingly good at zero-shot prompting. It’s easier than ever to generate working code. But without proper test coverage, version control, documentation, and a broader engineering mindset, that code is rarely maintainable.
As the project grows, and the LLM starts to struggle with the expanded context, errors will creep in. Without a human engineer to step in and take control, the result is often buggy, unscalable, or completely broken code.
AI-Driven Development
To get the most out of AI in software development, you need more than just an API key and a flashy demo. It requires a mindset shift, tooling access, and a foundational understanding of how LLMs and AI agents actually operate. Over the past few years, I’ve seen a clear pattern: those who thrive with AI tools are the ones willing to rewire their habits and adapt their workflows from the ground up.
Here are the key ingredients I believe are essential:
Willingness to replace your existing habits
This might be the biggest hurdle—especially for experienced developers or entire organizations. If you’ve been coding a certain way for years, it’s hard to suddenly embrace a new approach. There’s also an underlying fear: what if AI replaces my job?
It’s easy to try a random AI tool, get underwhelmed, and label the whole thing a gimmick. But this mindset misses the point. Modern LLMs aren’t static; they’re improving month over month. If you’re skeptical, I encourage you to compare GPT-4o with llama-3.2-1b, which runs locally as part of my awesome localstack. You’ll quickly notice the performance delta. These tools are on a steep improvement curve—and it’s unlikely to flatten anytime soon.
Access to the latest tools/models/APIs/IDEs
This is a no-brainer: if you want to work at the edge, you need access to the edge. That means working with the newest models, APIs, and dev environments.
But there’s a trade-off. Many of these tools have murky privacy policies, poor auditability, or are vulnerable to exploits like prompt injection. The tech will improve, but is your company willing to absorb that risk today?
LLM and AI agents understanding
Two years ago, when I first got hooked on AI and started presenting my learnings at conferences, I created a slide ranking key success factors for effective AI use. The number one takeaway?

That hasn’t changed.
If you don’t grasp the fundamentals—token limits, function calling, memory mechanisms, tool access, search strategies—you’ll constantly be frustrated or underwhelmed. AI agents are LLMs with tools, memory, and orchestrated workflows. Do you understand how they retrieve and store knowledge? How they chain tasks or respond to failures?
For a deeper dive, check out article on how Cursor works or explore my simple AI agent implementation.
Santiago recommends:
Assuming you’ve been writing software like me, I’d recommend you learn as much as possible about AI and how to use it to write better code. With the excitement and the amount of information out there, this shouldn’t be hard.
Willingness to change your codebase
LLMs and AI agents thrive in environments that are designed for them. That may sound backward—shouldn’t the tools adapt to us?—but if you’re serious about integrating AI into your dev loop, your codebase has to evolve too.
Here’s what that looks like in practice:
- Cursor has a hard limit of 250 lines per file. Will you enforce this via linting?
- Agents prefer clear, descriptive filenames. Will you rename your index.ts files?
- LLMs benefit from explanatory comments. Will you tolerate more in-code documentation?
- Tests matter. Are you investing in them, and optimizing their runtime?
- Docs matter. Will you keep them up to date?
- Separation of concerns matters. Will you refactor into clean, modular domains?
- Consistency matters. Will you maintain shared Cursor rules across the team?
I’m not saying you have to do all of this. But if you want to truly get the most out of AI tools—especially agents—you need to be willing to adapt your codebase. These tools perform best when working within well-structured, predictable environments. The more you align your architecture and workflow with the strengths of LLMs, the more value you’ll extract from them.
Costs
Integrating AI tools into the development workflow offers significant benefits but also introduces notable expenses. Currently, I subscribe to both ChatGPT Plus and Cursor Pro, each at $20 per month. These subscriptions provide access to advanced AI models and enhanced features that are integral to my coding activities.
While these tools enhance productivity, the cumulative costs can be substantial. Cursor Pro, for instance, includes 500 fast premium requests per month; exceeding this limit results in a significant slowdown, reducing productivity. To manage this, I consciously preserve these fast requests, utilizing them judiciously for tasks that demand higher performance, and relying on standard completions or copy-pasting from ChatGPT for less intensive operations.
I’d love to try Claude Code some day.
Think Like an Agent
To fully leverage AI agents, you need to show a bit of empathy for how they operate. When you start a new session, your agent knows almost nothing about your codebase—it starts from zero. The agent is like a fresh developer just dropped into your repo, trying to figure things out by poking around.
Terminal Awareness & Codebase Expectations
The agent begins by exploring your project using the terminal. It runs shell commands to understand your project structure and tooling. However, it’s important to remember that the agent expects certain conventions—especially in statically typed ecosystems like Java. For example:
- Production code is expected in
src/main/java - Tests in
src/test/java
If your structure deviates from these conventions, or if there’s unexpected coupling between classes, the agent might completely miss the relationships—unless you explicitly point them out.
Maintaining a consistent and conventional structure improves the agent’s understanding and productivity. Avoiding overly clever abstractions and directory layouts pays off when collaborating with AI.
Documentation as context
One of the best things you can do is write documentation—not just for humans, but for the agent.
If you explore my frontend and backend repositories, you’ll see that I maintain detailed README.md files. These serve as a reliable entry point for the agent to build a mental model of the project. I also ask the agent to review example files to learn naming conventions, architecture patterns, and code style.
LLMs are very good at generating documentation, so I lean into that strength. I often ask the agent to generate README content, endpoint descriptions, or summaries. My documentation coverage has increased significantly—especially for personal projects—simply because it’s so effortless now.
Since my application exposes a standard REST API, I also make sure the API docs are polished. These docs give the agent all it needs to interact with the backend via the frontend repo, making tasks like generating TypeScript interfaces a breeze.
Feedback Loops (Tests)
Before assigning a task to an agent, you should give it a clear feedback loop.
Agents understand exit codes, so you need to provide them with scripts or commands where a 0 means success and any non-zero value signals failure. This feedback mechanism helps the agent know when it’s on the right track and when it needs to iterate.
This is where tests shine.
For Java projects, running ./mvnw test is a perfect feedback loop. The agent learns that passing tests mean no regressions. I often encourage the agent to:
- Run specific test classes first:
mvn test -Dtest=NewTest - Then run all tests:
mvn test
This two-step flow gives fast feedback and confidence. I also keep test coverage high, especially since Sonnet excels at writing tests.
Ad-hoc scripts
The agent should be able to:
- Start, stop, and restart the server - example script
- Check whether the server is running - example script
- Query logs and monitor runtime behavior
These are basic capabilities, and the scripts required to support them are trivial to generate with LLMs. Your job is simply to expose the right paths and ensure the logs contain helpful diagnostic information.
I also prompt the agent to use curl to interact with the API. Combined with proper API docs, this gives it enough understanding to reason about the service layer without manual intervention.
This setup works so well that I rarely run into frontend issues related to missing or broken backend functionality.
MCP
The Model Context Protocol (MCP) is an open standard introduced by Anthropic to streamline how LLM applications interact with external tools and data sources.
It acts as a middleware layer between the LLM and the application, offering a standardized interface for accessing APIs, files, memory stores, and more—without custom integration work for each new system. Think of it as a protocol-driven, plug-and-play system for LLM-aware tooling.

I currently use only the official MCP Playwright implementation from Microsoft, and I have to say—it feels like a glimpse into the future. It’s clean, modular, and genuinely useful for test automation.
If you’re a test engineer, I highly recommend giving MCP a try. It changes how you think about test orchestration, browser control, and LLM-driven validation.

Workflow and examples
Enough theory—let’s get into the actual workflow I’ve been using successfully for a while now. This approach likely has room for optimization (e.g., using more powerful models like o1-pro for planning or Claude 3.7 Sonnet MAX for execution), but I find it strikes a great balance between cost and performance.
Step 1: Move yourself to educated vibe coding area
I’ve touched on this earlier, but it bears repeating: to use AI effectively, you need to understand what the agent is doing and be ready to take over at any point. That may not align with the “no-code” vision some people promote—but it’s the current reality.
One of the best ways to build this skill is through deep research using tools like OpenAI, xAI, or Perplexity. For instance, when I needed to build websocket-based functionality for my localstack, I simply asked ChatGPT to list implementation examples in both React and Java. I followed a similar path when integrating SSE (Server-Sent Events) with my local Ollama setup.
Tip: Learning with ChatGPT is severely underrated. It gives you a stress-free way to explore new concepts and test your understanding—instantly and interactively.
Step 2: Ingest the codebase
I use gitingest to flatten the codebase into a single file, or I copy it manually if needed. For private projects, I prefer the library version of the tool.
When working with larger projects that don’t fit within the model’s context window, I exclude files strategically—for example, skipping E2E tests or page objects. This is one of the reasons why AI excels with smaller, modular projects.
Some enterprise-level codebases may be monoliths. They often lack separation of concerns, and their test suites are slow, making the feedback loop longer and more fragile. In such environments, LLMs struggle to connect related classes or features, especially when those connections aren’t explicit.
It’s not uncommon to see posts on X or Reddit where someone is initially amazed by AI, only to get frustrated as their codebase grows. Once the repo no longer fits inside Cursor Sonnet’s 50k token window, things start to fall apart. Poor directory structure and misplaced files—usually from less experienced devs—lead to confusion, and the agent fails. That’s when people start claiming that “Cursor has been nerfed.” In reality, they’ve hit the limitations of context management.
Step 3: Ask a Thinking Model for a Detailed Implementation Plan
This is arguably the most important step. Use a model with strong reasoning capabilities and a sufficiently large context window. I personally use o1 and keep an eye on the Tracking AI leaderboard to pick top-performing models for planning tasks.
Example prompt:
I have frontend with the following codebase:
{{ CODE DUMP FROM GITINGEST }}
==================
I'd like my frontend to have a tab which shows llm chat integrating with the following endpoint:
private final OllamaService ollamaService;
@Operation(summary = "Generate text using Ollama model")
@ApiResponses(value = {
@ApiResponse(responseCode = "200", description = "Successful generation"),
@ApiResponse(responseCode = "400", description = "Invalid request", content = @Content),
@ApiResponse(responseCode = "401", description = "Unauthorized", content = @Content),
@ApiResponse(responseCode = "404", description = "Model not found", content = @Content(
mediaType = "application/json",
schema = @Schema(implementation = ModelNotFoundDto.class)
)),
@ApiResponse(responseCode = "500", description = "Ollama server error", content = @Content)
})
@PostMapping(value = "/generate", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<GenerateResponseDto> generateText(@Valid @RequestBody StreamedRequestDto request) {
return ollamaService.generateText(request)
.doOnSubscribe(subscription -> log.info("Starting stream"));
}
It is a proxy toward ollama api/generate streamed endpoint
================
I want each chunk to be displayed live in stream-like chatgpt-like fashion on the frontend.
Basically I wish to create a simplified llm-chat experience for my website
===============
Prepare a very detailed implementation plan which will guide Claude 3.7 AI agent.
Split the plans into actionable steps. Include tests in the plan (decide how many react testing library and playwright tests do we need).
If something is unclear ask question, if not create a plan in markdown. Do not omit any details,
remember that the AI agent is a dumber LLM hence you need to guide it
Examples:
The prompt is structured with these key elements:
- Code dump (from gitingest)
- Additional context (requirements, endpoints, backend logic)
- Detailed request for a plan, tailored to execution by a less “thoughtful” agent
Step 4: Execute the plan in Cursor
Once the plan is in place, it’s time to execute. This is where I bring in Cursor with the Sonnet agent, which is highly capable at structured, test-first coding.
Initial Prompt to Cursor’s Agent:
Familiarise yourself with the project, read your rules, example components/logic files,
RTL tests and playwright tests. See @README.md as well
You first task is to update @websockets.md to be nicely formatted file.
Add tests to implementation plan and maybe refine it slightly (if needed)
Next, start implementing the plan. Start with RTL tests only,
iterate to make them pass if needed (you can run them independently).
Let's do Playwright tests later, I wish to see the outcome UI first.
Frontend is already running on port 8081 with hot reload.
Full backend changes are available in @backend-changes.md and
api docs can be accessed via curl http://localhost:4001/v3/api-docs
This setup contains everything the agent needs:
- Clear instructions to explore the codebase
- References to internal documentation and example files
- Incremental execution instructions
- Ordered test strategy: start with RTL, Playwright later
Unfortunately, Cursor doesn’t currently allow exporting conversation history, so I can’t share the full agent interaction logs. That said, the prompts and structure outlined above closely mirror how I work with the agent day-to-day.
Closing questions to ponder
- At which point can we say that we’ve automated the software development process?
- Is it a revolution yet?
- What does it mean to Software Engineers?
- What does it mean for Product Managers?
- What does it mean for DevOps Engineers?
- What does it mean for QA Engineers?
Let me know what you think in the comments below.
AI posts archive
- The rise of AI-Driven Development
- From Live Suggestions to Agents: Exploring AI-Powered IDEs
- AI Vibe Coding Notes from the Basement
- How I use AI
- How does Playwright MCP work?
- AI Tooling for Developers Landscape
- Playwright Agentic Coding Tips
- Mermaid Diagrams - When AI Meets Documentation
- AI + Chrome DevTools MCP: Trace, Analyse, Fix Performance
- Test Driven AI Development (TDAID)
- Testing LLM-based Systems
- Building RAG with Gemini File Search
- Playwright MCP Security
Tags: AI
Categories: AI
Updated: